Novedades ECMAScript 2018 (ES9)
6 minutos de lectura
Fecha: 2/11/2018
La verdad es que no sabía muy bien como titular la entrada para posicionarla medianamente bien, al final ha quedado Novedades ECMAScript 2018 (ES9), de lo que quiero hablar hoy es de las novedades que ha consolidado el lenguaje Javascript en su standard este año 2018.
El problema es que a esto le podemos llamar ECMAScript 2018, ES2018, ES9. Dicho esto que sepáis que es lo mismo, y también que las novedades del lenguaje no se implementan de forma automática en los navegadores, de manera que no esperes escribirlo y que funcione directamente, aunque siempre puedes transpilarlo.
Dicho esto, que sepáis que Javascript saca un standard todos los años desde el 2015, os dejo una tabla para que veáis los que tenemos por ahora…
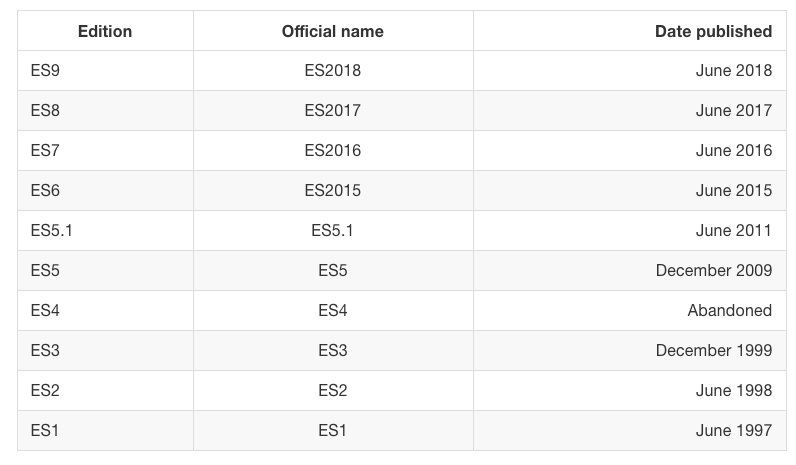
Y ahora por fin hablemos de que hay de nuevo en la última versión.
Novedades ECMAScript 2018 (ES9)
Algunas de las novedades más destacadas son las que afectan a expresiones regulares. Veamos las 4 que tenemos.
s (dotAll) flag for regular expressions de Mathias Bynens
En las expresiones regulares el punto . coincide con un solo carácter, independientemente de qué carácter es. En ECMAScript, hay dos excepciones a esto:
.No coincide con los astral characters. Aunque su usas el flagu(unicode) lo solucionas (pero tienes que acordarte)..No coincide con los caracteres terminadores de línea (Que son unos cuantos).
En primer lugar explicar de que va eso de los astral characters porque yo también cuando lo leí la primera vez flipé un poco. Se les considera a todos los caracteres que no son Basic Multilingual Plane que son el primer plano de los caracteres unicode y contiene caracteres para casi todos los idiomas modernos y una gran cantidad de símbolos.
Un ejemplo de astral characters sería un emoji, y para que veáis el problema, mirad este código (y si quieres te abres la consola del navegador y lo pruebas).
/^.$/.test('😀')
// Devuelve false
La expresión regular comprueba que la cadena comience por un caracter, pero no detecta el emoji, como dijimos con el flag u (unicode) ya lo devuelve bien.
/^.$/u.test('😀')
// Devuelve true
Y ahora vamos con el segundo caso (que son los que realmente se han corregido), los caracteres que terminan linea, que son estos…
- U+000A LINE FEED (LF) (
\n) - U+000D CARRIAGE RETURN (CR) (
\r) - U+2028 LINE SEPARATOR
- U+2029 PARAGRAPH SEPARATOR
/^.$/.test('\n')
// Devuelve false
Existen workarounds para arreglar eso, pero ahora en ES9 proponen algo distinto, nos dejan que podamos usar siempre el punto incluso cuando tengamos caracteres terminadores de línea, lo cual reduce la complejidad a la hora de crear las ya de por si complejas expresiones regulares.
Por cierto si quieres saber más sobre la sintaxis de las expresiones regulares puedes ver este artículo que publiqué hace tiempo.
Y esto lo consiguen añadiendo un nuevo flag /s (single line), que viene a hacer que todo se trate como una sola linea, e interpreta los dichosos caracteres de salto. Veamos un ejemplo más completo.
/hello.world/.test('hello\nworld')
// devuelve false
Con el nuevo flag ya funciona…
/hello.world/s.test('hello\nworld')
// devuelve true
RegExp named capture groups de Gorkem Yakin y Daniel Ehrenberg
Ahora podemos añadir grupos de captura a nuestras expresiones regulares y la verdad es que es un cambio muy importante y que añade mucha potencia. El ejemplo más claro para ilustrarlo es el de parsear un fecha pues tenemos por ejemplo bloques para el año, el mes, el día…
Esto antes era posible con un código de este estilo…
const REGEX = /([0-9]{4})-([0-9]{2})-([0-9]{2})/
result = REGEX.exec('2018-11-02');
console.log(result[0]); // devuelve 2018-11-02
console.log(result[1]); // devuelve 2018
console.log(result[2]); // devuelve 11
console.log(result[3]); // devuelve 02
Hasta aquí todo bien, hicimos los grupos usando los paréntesis, y después atacamos al array resultante usando los indices para extraerlos.
Lo que permite ES9 es que asignemos un nombre a esos grupos, para que no tengamos que pelearnos con los índices y con el problema que es asignar las cosas por posición en vez de por nombre (sobre todo cuando refactorizamos el código y hacemos modificaciones).
Esta es la nueva manera!
const REGEX = /(?<year>[0-9]{4})-(?<month>[0-9]{2})-(?<day>[0-9]{2})/
result = REGEX.exec('2018-11-02');
console.log(result.groups.year); // devuelve 2018
console.log(result.groups.month); // devuelve 11
console.log(result.groups.day); // devuelve 02
RegExp Lookbehind Assertions de Gorkem Yakin, Nozomu Katō y Daniel Ehrenberg
El tema de Assertions seguro que os suena a todos aquellos que hacéis pruebas unitarias por ejemplo, sirve para comprobar si una afirmación es correcta o no, devuelve un booleano para que nos entendamos.
Sobre esto no hay mucho que entender, solo ver el funcionamiento, por supuesto como es un booleano tendremos Assertions positivas y negativas, un ejemplo de positiva es este…
'$lorem #lorem @lorem'.replace(/(?<=#)lorem/g, 'ipsum')
// devuelve $lorem #ipsum @lorem
Creo que se ve claro, para hacer una aserción positiva usamos esta sintaxis (?<=…)
Esto quiere decir que nuestra expresión regular /(?<=#)lorem/g busca la palabra lorem en toda la cadena pero solamente cuando se cumpla que vaya precedido por el caracter #
Una vez lo encuentra se cambia la palabra lorem (no #lorem, la aserción no se incluye) por ipsum.
De ahi que transforme ‘$lorem #lorem @lorem’ en ‘$lorem #ipsum @lorem’
La aserción negativa tiene esta sintaxis (?<!…), y usando el ejemplo anterior…
'$lorem #lorem @lorem'.replace(/(?<!#)lorem/g, 'ipsum')
// devuelve $ipsum #lorem @ipsum
Se ve claro que es la inversa.
RegExp Unicode Property Escapes de Mathias Bynens
También podremos buscar caracteres mencionando sus propiedades Unicode, es muy sencillo pensemos en que lo que queremos es que nuestra expresión regular controle una letra que pertenezca al alfabeto griego.
Voy a escoger la letra alpha
/p{Script=Greek}/u.test('α')
// devuelve true
Con el \p{Script=Greek} he conseguido que haga match contra cualquier caracter del alfabeto griego!
Hasta aqui las novedades que afectan a las expresiones regulares (que como veis no son pocos), ahora veamos otras novedades también muy interesantes y que vamos a usar bastante.
Asynchronous Iteration de Domenic Denicola
Las iteraciones asíncronas es una novedad importante, y sí has leído bien, vas a combinar un bucle for con una promesa nada menos, me encanta!
for await (const line of readLines(filePath)) {
console.log(line);
}
Esto va a ser muy util cuando tengamos que hacer tareas pesadas dentro de un bucle y no queramos retrasar la ejecución del resto del código. Lo que hace internamente es crear iteradores asíncronos por cada iteración del bucle que esperan la respuesta de la promesa.
Rest/Spread Properties de Sebastian Markbåge
Otra funcionalidad muy chula es la de las propiedades Rest y Spread. El término seguro que nos suena porque ya usábamos esto en los argumentos que les pasamos a las funciones, porque se aplicaba esta técnica a los arrays, concretamente desde ES6 que ya los teníamos.
Pues ahora podemos aplicar esto a las propiedades de un objeto!
El concepto es el mismo y tampoco lo voy a explicar aquí, esto es como se aplican las propiedades rest:
let { x, y, ...z } = { x: 1, y: 2, a: 3, b: 4 };
x; // 1
y; // 2
z; // { a: 3, b: 4 }
Como se ve las propiedades que tienen el mismo nombre se copian y todas las que no existen van contra la propiedad rest. Este es el ejemplo oficial, pero por si no se ve claro aun lo podemos complicar más…
let { a, d, ...z } = { a: 12, b: 15, c: 3, d: 8, e: 10, z: 7 };
a; // 12
d; // 8
z; // { b: 15, c: 3, e: 10, z: 7 }
Como vemos aquí encuentra ‘a’ y ‘d’, y les asigna el valor correspondiente, pero también tenemos una variable ‘z’, ¿se limita a asignarle solo el valor correspondiente?. No, no se limita a eso porque es la propiedad rest, así que recoge todas las no asignadas.
Ahora vamos con spread que es lo contrario, y tampoco necesita explicación este sería el resultado usando el primer ejemplo.
let n = { x, y, ...z };
n; // { x: 1, y: 2, a: 3, b: 4 }
Como vemos ha hecho el proceso contrario, y si ahora usara el segundo ejemplo haría esto.
let n = { a, d, ...z };
n; // { a: 12, d: 8, b: 15, c: 3, e: 10, z: 7 }
Promise.prototype.finally de Jordan Harband
La última novedad por comentar es que dentro de las funciones de callback de las promesas se ha incluido una llamada finally que como su nombre indica se invoca siempre.
Ahora por tanto tenemos then, catch y finally como posibles respuestas de una promesa.
Es posible que si usabas alguna librería tipo jQuery, su implementación de las promesas ya incluyera un método para hacer esto, por ejemplo, en jQuery podíamos usar objetos deferred para desacoplar las funciones de callback, y una de esas funciones era always(), aquí os dejo el link para que comprobarlo, que viene a hacer lo mismo que la llamada finally de la que acabamos de hablar.
De manera que puede que ya estés familiarizado con su uso, y me parece estupendo que estas funcionalidades que ya se implementan de forma externa con librerías de terceros se lleven al propio lenguaje para que podamos usarlo de forma nativa.
Hasta aquí el artículo, espero que os sea de utilidad.